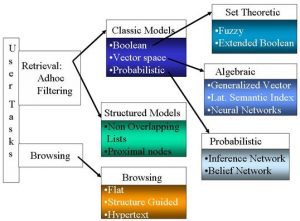
Model Model Sistem Temu Balik Informasi
Model Klasik
- Boolean
- Vector
- Probabilistic
Model Terstruktur
- Non Overlapping List
- Proximal Nodes
(Model Informasi Retrival)
MODEL KLASIK
- Model Boolean
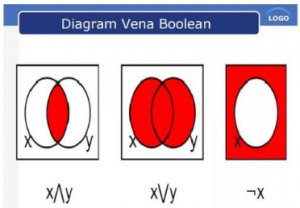
Dengan model boolean maka pencarian query dilakukan dengan fungsi-fungsi logika yang umum seperti OR, AND, XOR,NOT,NAND, NOR dan lain sebagainya diantara kata yang diinginkan. Contohnya jika query Q= ( K1 AND K2) OR ( K3 AND ( NOT K4)).
Pencarian Boolean akan mengambil semua dokumen yang di indeks oleh K1 dan K2, seperti halnya semua dokumen yang diindeks oleh K3 yang tidak termasuk dalam indeks K4. Suatu cara mengimplementasikan pencarian Boolean adalah melalui inverted file. Kita menyimpan daftar tiap kata kunci dalam sebuah kata dan tiap kata menunjuk alamat dokumen yang mengandung kata tertentu itu untuk memaksimalkan query kita melakukan set terhadap operasi dan menghubungkannya dengan daftar koleksi (K-List).
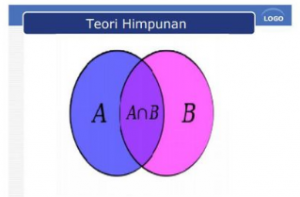
Model Boolean dibagi menjadi 2 yaitu :
- Model Himpunan Fuzzy
Misalkan U adalah himpunan semesta. Fuzzy subset dari U dikarakteristikkan dengan fungsi keanggotaan (membership function) mA, dimana : μA : U → [0,1] setiap uÎU dipetakan kedalam nilai biner [0,1], atau μA : U → [0,1]. Dengan demikian setiap elemen diberikan nilai biner yang mengindikasikan nilai keanggotaan elemen didalam himpunan.
Pada sistem temu kembali, model himpunan fuzzy merupakan perluasan dari model Boolean retrieval. Ada beberapa perluasan yang diperoleh dengan menggunakan model himpunan fuzzy:
- Partially matching, berdasarkan term-term correlation matrix
- Direpresentasikan seperti thesaurus
- Melakukan perhitungan berdasarkan perbandingan antara dokumen yang mengandung pasangan term (pair of terms) dengan jumlah dokumen yang mengandung term tersebut.
- Model Extended Boolean
Prinsip utama dari teknik Extended Boolean adalah :
- Dokumen direpresentasikan dalam ruang term berdimensi n
- Koordinat x, y dan z ditentukan dengan menggunakan bobot term
- Tergantung pada conjunction atau disjunction :
- Menentukan vektor jarak dari (0,0)
- Menentukan vektor jarak dari (1,0)
- Menggunakan konsep p-norm
- Perluasan karakteristik dari extended Boolean
- Menghitung jarak.
Kelebihan dan kekurangan dari Model Boolean
- Kelebihan dan Kekurangan Model Boolean, Kelebihannya adalah lebih mudah bagi user yang berpengalaman. Model Boolean merupakan model sederhana yang menggunakan teori dasar himpunan sehingga mudah diimplementasikan.Model Boolean dapat diperluas dengan menggunakan proximity operator dan wildcard operator.Adanya pertimbangan biaya untuk mengubah software dan struktur database, terutama pada sistem komersil.
- Kelemahannya adalah kerumitan dalam penggunaan bahasa query dan akan membingungkan pengguna yang biasa. Model Boolean tidak menggunakan peringkat dokumen yang terambil. Dokumen yang terambil hanya dokumen yang benar-benar sesuai dengan pernyataan boolean/kueri yang diberikan Sehingga dokumen yang terambil bisa sangat banyak atau bisa sedikit. Akibatnya ada kesulitan dalam mengambil keputusan.Teori himpunan memang mudah, namun tidak demikian halnya dengan pernyataan Boolean yang bisa kompleks. Akibatnya pengguna harus memiliki pengetahuan banyak mengenai kueri dengan boolean agar pencarian menjadi efisien.Tidak bisa menyelesaikan partial matching pada kueri.
- Model Vector
Dalam sistem IR, kemiripan antar dokumen didefinisikan berdasarkan representasi bag of words dan dikonversikan ke suatu model ruang vektor (vector space model – VSM). Pada VSM, setiap dokumen di dalam database dan query pengguna direpresentasikan oleh suatu vektor multi-dimensi.
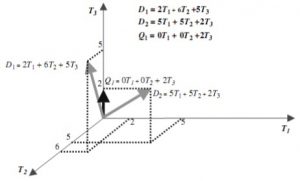
(Gambar Model Vektor)
Pada model ruang vektor, pembobotan terhadap term dilakukan dengan mengalikan bobot lokal tf dan bobot global idf, dikenal dengan pembobotan tf-idf. Metode pembobotan ini dilakukan dengan memberikan bobot kepada term yang penting. Artinya, term yang jika muncul di suatu dokumen maka, dokumen tersebut dapat dianggap relevan dengan query pengguna.
- Model Probabilistic
Model probabilistik adalah model sistem temu kembali informasi yang mengurutkan dokumen dalam urutan menurun terhadap peluang relevansi sebuah dokumen terhadap informasi yang dibutuhkan. Beberapa model yang juga dikembangkan berdasarkan perhitungan probabilistik yaitu, Binary IndependenceModel, model Okapi BM25, dan Bayesian Network Model (Manning dkk, 2009).
MODEL TERSTRUKTUR
- Model Non Overlapping
Sistem yang menggunakan model ini akan membagi-bagi dokumen sebagai wilayah teks tertentu misalnya dengan mengikuti stuktur dokumen (bab, sub-bab, judul, sub-judul, gambar, foto, tabel dan seterusnya) kemudian untuk masing-masing wilayah ini dilakukan pengindeksan yang tidak saling menindih (non overlapping)
- Model Proximal nodes
Model IR ini menggunakan beberapa struktur indeks yang memiliki hirarki independen terhapap sebuah dokumen. Masing-masing dari indeks ini merujuk ke struktur dokumen (bab, sub-bab, judul, sub judul, gambar, foto tabel dan seterusnya)yang dinamakan nodes. Pada masing-masing node inilah ada rujukan ke bagian dari dokumen yang mengandung teks tertentu.
REFERENSI
- Model Pengertian Model TBI.
http://docplayer.info/37181830-Browsing-dan-searching-sebagai-sarana-temu-kembali-sumber-sumber informasi-dalam-perpustakaan-digital.html
- Metode Dan Model Sistem Temu Balik Informasi.
https://computernet-news.blogspot.co.id/2017/04/metode-dan-model-sistem-temu-balik.html
- Giat Karyono dan Fandy Setyo Utomo Temu Balik Informasi Pada Dokumen Teks Berbahasa Indonesia Dengan Metode Vector Space Retrieval Model. ISBN , Seminar Nasional Teknologi Informasi & Komunikasi Terapan 2012 (Semantik 2012)
- Sistem Temu Kembali Informasi.
http://zero-fisip.web.unair.ac.id/artikel_detail-68838-
https://putuandreaswaranu.wordpress.com/2015/03/10/pemodelan-sistem-temu-kembali-informasi-boolean/
FILE PPT BISA DIDOWNLOAD DISINI : PPT TBI-P2