TUGAS
Temu Balik Informasi
LATENT SEMANTIC INDEXING
Nama kelompok :
- Desi Rahmawati 11.0273
- Maulana Akbar 11.0260
- Resni Novelalita 11.0258
- Riki Aji Pamungkas 11.0317
- Kurnia Aswin Nuzul 11.0270
- Pradita Novianty 11.0298
- Inggita A. M. 11.0269
- Semuel Haryanto 11.0250
- Dimas Adhi Nugroho 11.0253
STMIK AMIKOM PURWOKERTO
2017/2018
PRINSIP DAN KONSEP ALGORITMA LATENT SEMANTIC INDEXING
- Prinsip Latent Semantik
Latent semantik sebuah metode baru yang digunakan dalam algoritma search engine yang sedang dikembangkan oleh google Coorporation. Dengan menggunakan metode latent semantik digunakan oleh google untuk menganalisis kata kunci pencarian dengan cara yang baru, dan bukan lagi menggunkan sistem berdasarkan kecocokan kata secara leksikat. Kata yang dicari disini bukan hanya kata kuncinya saja yang terindex seperti pada algoritma yang digunakan pada umumnya, akan tetapi kata-kata yang berhubungan dengan kata kunci yang akan dicari.
Tujuan dari Algoritma Latent Semantik yaitu untuk mendapatkan suatu pemodelan yang efektif digunakan untuk mempresentasikan sebuah hubungan antara kata kunci yang dicari dan dokumen yang akan dicari. Dari sebuah sekumpulan kata kunci yang tidak lengkap dan tidak sesuai menjadi sekumpulan objek yang saling berkaitan atau berhubungan.
Sumber : Ferdian Edward, Hadisaputra Rian, Madjid Nurkholis. 2005, Penerapan Metode Latent Sematic Indexing pada Search Engine. Institut Teknologi Bandung.
Metode latent semantic
- dengan membandingkan dua term
disini akan membandingkan hasil kali titik dari dua baris vector X dengan mencerminkan bahwa dua term tersebut memiliki pola yang sama dalam sebuah dokumen.
- membandingkan 2 dokumen yang berbeda
dengan cara membandingkan hasil kali titik dari dua kolom vektor.
- membandingkan sebuah term dengan dokumen
Sumber : Ferdian Edward, Hadisaputra Rian, Madjid Nurkholis. Penerapan Metode Latent Sematic Indexing pada Search Engine. Institut Teknologi Bandung. http://informatika.stei.itb.ac.id/~rinaldi.munir/Stmik/Makalah/MakalahStmik37.pdf
- Konsep Latent Semantic Indexing (LSI)
Konsep Metode Latent Semantic Indexing (LSI) merupakan metode IR yang membangun koleksi dokumen dalam bentuk ruang vector dengan menggunakan aljabar linier, yaitu singular value decomposition. Pada umumnya setiap dokumen akan dikatakan relevan dengan query apabila sebuah dokumen memuat kata atau kalimat yang sama dengan query atau memuat kata atau kalimat yang bermakna sama dengan query. Metode latent semantic adalah sebuah metode yang diimplemntasikan dalam Information Retrieval (IR) system dalam mencari dan menemukan sbeuah informasi berdasarkan makna secara keseluruhan (conseptual topic atau meaning) dari sebuah dokumen bukan hanya makna perkata.
Metode latent semantic indexing
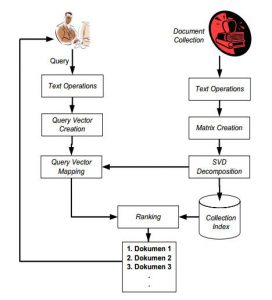
Gambar 1. Proses alur dari metode semantic indexing
Dari gambar 1 dijelaskan bahwa alur proses dari metode latent indexing dibagi menjadi 2 kolom yaitu kolom sebelah kiri tentang query dan kolom sebelah kanan tentang koleksi dari dokumen. Pada query akan diproses melalui operasi teks, kemudian vektor akan dibektuk. Vektor yang dibentuk akan dipetakan menjadi vektor query terpeta (mapped query vektor). Dalam pembentukan query diperlukan hasil dekomposisi nilai singular dari koleksi dokumen. Pada koleksi dokumen dilakukan operasi teks pada koleksi dokumen yang selanjutnya matriiks kata dokumen. Selanjutnya, hasil dekomposisi akan disimpan dalam collection index. Pada proses ranking dilakukan dengan menghitung relevansi antara vektor query berpeta dengan collection index. Selanjutnya hasil perhitungan akan ditampilkan kepada user atau pengguna.
Sumber : http://hbunyamin.itmaranatha.org/Papers/TESIS_hendra_final.pdf
Secara umum, konsep LSI meliputi beberapa point sebagai berikut:
a. Text Operations pada Query dan Document Collection.
Query dari pengguna dan koleksi dokumen dikenakan proses text operations. Proses text operations meliputi,
- Mem-parsing setiap kata dari koleksi dokumen,
- Membuang kata-kata yang merupakan stop words,
- Mem-stemming kata-kata yang ada untuk proses selanjutnya.
b. Matrix Creation
Hasil text operations yang dikenakan pada koleksi dokumen dikenakan proses matrix creation. Proses matrix creation meliputi,
- Menghitung frekuensi kemunculan dari kata,
- Membangun matriks kata-dokumen seperti diilustrasikan
c. SVD Decomposition

Matriks kata dokumen yang terbentuk, jika A berukuran mxn, maka selanjutnya dikenakan dekomposisi SVD (Singular Value Decompotion). Hasil SVD serupa 3 (tiga) buah matriks seperti yang akan diilustrasikan pada gambar III.6. Matriks A dapat ditulis menjadi A=.
d. Query Vector Creation

Vektor query, q dibentuk seperti membangun sebuah kolom dari matriks kata-dokumen.
Contoh vektor query, q adalah
Dengan , j= 1,2,…, m adalah frekuensi kemunculan kata pada Query.
e. Query Vector Mapping
Point (3)(v) di atas telah memberikan nilai r yang merupakan dimensi dari ruang vektor hasil perkalian baru. Selanjutnya, vektor query q dipetakan ke dalam ruang vektor berdimensi r menjadi Q, yaitu

f. Ranking
Kolom-kolom pada matriks pada point (3)(v) adalah vektor-vektor dokumen yang digunakan dalam menghitung sudut antara vektor dokumen dan vektor query.
Ranking dari dokumen relevan ditentukan oleh besar sudut yang dibentuk oleh vektor query dan vektor dokumen. Semakin kecil sudut yang dibentuk, semakin relevan query dengan dokumen.
g. Hasil Akhir
Perhitungan cosinus sudut antara query, Q dan dokumen D j, j =1,2,…,n diperoleh dan diurutkan berdasarkan dari yang paling besar sampai yang terkecil.
Nilai cosinus sudut yang terbesar menunjukkan dokumen yang paling relevan dengan query.
- Algoritma dalam Algoritma Latent Semantic
1. Algoritma Probabilistic pada jurnal Implementasi Algoritma Probabilistic Latent Semantic Analysis Dalam Pengklasteran Dokumen Berbasis Topik.
Pada jurnal implemnetasi algoritma probabilistic latent semantic analysis dalam pengklasteran dokumen berbasis topik penggunaan algoritma probablistic digunakan untuk pendekatan probabilitas dnegan dua model contoh dokumen dan kata. Probabilistic dapat digunakan untuk menidentifikasi kata-kata dengan beberapa arti dan kemudian memetakan kata-kata tersebut dalam berbagai topik. Probalilistic algoritma biasanya digunakan dalam aplikasi temu balik informasi, pengolahan bahasa alami. Dan plsa juga dapat digunakan untuk mengelompakan kata ke dalam topik-topi yang belum diketahui.
Algoritma yang digunakan :
- Menentukan jumlah topik (z) yang nantinya didapat melalui Metode Hartigan Index.
- Menginalisasi secara random 3 parameter dengan p(z), p (d|z), p (w|z).
Dimana
P (z) = probabilistik topik
P (d|z) = probabilitas dokumen yang mengandung topik.
P (w|z) = probabilitas kata yang terdapat topik.
- Menghitung untuk measing-masing parameter menggunakan Expectation Maximization.
Sumber : Putra Suwiprabayanti Gde Ayu Ida, Purwitasari Diana, Siahaan Oranova Daniel. Implementasi Algoritma Probabilistic Latent Semantic Analysis Dalam Pengklasteran Dokumen Berbasis Topik. Insitutut Teknologi Sepuluh November Surabaya. http://digilib.its.ac.id/public/ITS-Undergraduate-17658-paper.pdf
Power Point : LSI_TBI