Sistem Temu Kembali Informasi Multimedia
A. Sistem Temu-kembali Informasi Multimedia (Multimedia Information Retrieval System)
Tujuan dari Sistem Temu-kembali Informasi Multimedia adalah untuk memberikan jawaban terbaik yang sesuai dengan kebutuhan pengguna informasi. Umumnya, dalam sistem informasi, pengguna mengekspresikan kebutuhan informasi mereka dalam bentuk pertanyaan dan kemudian sistem mencocokan kueri ke database untuk menemukan informasi yang relevan. Dalam kasus informasi multimedia, kebutuhan informasi pengguna dapat dihubungkan dengan seluruh dokumen –dokumen yang ada.
Untuk informasi multimedia, kebutuhan informasi dapat mencakup informasi multimedia secara keseluruhan atau komponen audio-visual, misalnya urutan, layar, ay at-ayat, dialog. Dalam basis informasi mu ltimedia, para peneliti mencoba untuk memfasilitasi akses ke bit informasi yang relevan dengan kebutuhan pengguna dan beradaptasi untuk menjawab kebutuhan informasi yang beragam.
a) Pengertian Sistem Temu-kembali Informasi Multimedia
Maghrebi berpendapat bahwa sistem informasi mu ltimedia adalah sistem informasi yang dapat memperhitungkan jenis informasi, karakteristik dan komponen (gambar, suara, teks) dalam rangka memungkinkan pengguna untuk memiliki akses ke informasi tersebut (Maghrebi, 2008, p2).
Menurut Peter S., Temu-kembali Informasi Multimedia adalah sebuah metodologi yang telah dikembangkan untuk mencari infomasi yang relevan didalam database multimedia, dalam hal ini disebut dokumen (Peter, 1997, p4). Joan mendefinisikan Sistem Temu-kembali Informasi Multimedia sebagai sebuah sistem untuk manajemen (penyimpanan, pengambilan,dan manipulasi) data beberapa media, seperti kombinasi data tabular/administratif, dokumen teks, gambar, spasial, sejarah, audio, dan data video (Joan, 2008).
b) Prinsip Sistem Temu-kembali Informasi Multimedia
Peter S. dalam Multimedia Information Retrieval menyatakan bahwa biasanya pengguna tidak pernah melihat dokumen yang diinginkan sebelumnya, dan jumlah dokumen yang relevan tidak diketahui (Peter, 1997, p4). Semua metode pencarian yang telah diterbitkan sejauh ini didasarkan pada salah satu dari dua prinsip-prinsip berikut:
- Prinsip Temu-kembali Berorientasi Penyimp anan (Storage Oriented Retrieval Prin ciple):
Jika dokumen disimpan dalam tempat yang cocok, maka akan mudah untuk mengambilnya di masa depan. Fokus utama dari prinsip berorientasi penyimp anan adalah organisasi dari “tempat yang sesuai” di mana dokumen yang akhirnya disimpan, atau dimana referensi dokumen yang disimpan (misalnya kartu indeks). Pendekatan yang mengikuti hasil prinsip dalam struktur informasi berupa klasifikasi, dan thesaurus (Lancaster, 1986).
- Prinsip Probabilitas Peringkat (Probablitiy Ranking Principle):
Jika respon sistem pengambilan referensi untuk setiap permintaan adalah peringkat dokumen dalam koleksi dalam probabilitas kegunaan bagi pengguna yang mengajukan permintaan, dimana probabilitas diperkirakan seakurat mungkin atas dasar apa pun data telah dibuat tersedia untuk sistem untuk tujuan ini, maka keseluruhan efektivitas sistem untuk penggunanya akan menjadi yang terbaik yang dapat diperoleh berdasarkan data (Robertson, 1977).
Dalam konteks perpustakaan digital, prinsip pertama belum dibenarkan sejauh ini. Prinsip probabilitas peringkat jelas lebih unggul daripada pendekatan penyimp anan tradisional yang berorientasi dalam dua hal. Pertama, prinsip probabilitas peringkat bisa dibuktikan secara matematis. Kedua, percobaan dibuat sejauh ini juga menunjukkan keunggulan prinsip probabilitas peringkat. Perlu dicatat, bagaimanapun, bahwa metode pengambilan penyimpanan berorientasi dan metode pengamb ilan berdasarkan prinsip probabilitas tidak sepenuhnya tidak berhubungan. Terdapat hubungan antara berbagai jenis metode pengambilan (Penyu dan Croft, 1992) dan (Wong dan Yao, 1995).
c) Komponen Penting dalam Sistem Temu-kembali Informasi Multimedia
Peter (Peter, 1997, p5) menuliskan ada 4 kelompok komponen yang penting, antara lain : dokumen multimedia, model Temu-kembali, analisis dokumen, dan teknik pencarian interaktif.
- Dokumen Multimedia: Sistem mampu menyimpan dokumen
- Dokumen yang disimpan terdiri dari data multimedia (teks, gambar audio, video, dll).
- Dokumen yang disimpan adalah semi terstruktur, yaitu mereka berisi data terstruktur serta data tidak
Dengan data yang terstruktur , atribut database khusus seperti tanggal lahir, no. karyawan, dan nama belakang. Dengan data yang tidak terstruktur, seperti Binary Large Objects (BLOBs), misalnya teks, gambar, audio, dan video rekaman. BLOBs tersebut dapat mengandung beberapa simbol yang dapat diinterpretasikan dalam cara yang tepat (misalnya perintah SGML).
- Model Temu-kembali: sistem mengadopsi model pengambilan yang mengoptimalkan efektivitas pengamb ilan sesuai dengan prinsip probabilitas
- Sistem merespon untuk permintaan dengan menyajikan daftar dokumen yang diurutkan dalam peringkat yang baik mewakili probabilitas sendiri maupun dapat dipetakan ke probabilitas dengan cara order preserving transformation.
- Skor ini sering disebut Retrieval Status Value (RSV) bergantung pada deskripsi dokumen yang terdiri dari informasi statistik yang tepat tentang fitur pengindeksan (misalnya fitur frekuensi atau frekuensi dokumen).
- Skor tersebut mungkin juga tergantung pada domain parameter yang diperkirakan dengan cara data tambahan, misalnya dengan cara pengumpulan pelatihan atau oleh thesaurus.
- Analisis Dokumen: dokumen diproses untuk mengumpulkan informasi statistik.
- Pengolahan dokumen adalah jenis pemrosesan sinyal ketika informasi yang tidak relevan maka akan Ketika menganalisis dokumen teks, kata-kata umum (misalnya, sebuah, untuk) dan akhiran (misalnya-ed,-ing) dapat dihapus karena mereka mengandung sedikit makna. Dalam kasus rekaman percakapan, pitch bisa dihapus karena kata yang sama dapat diucapkan dengan suara tinggi atau dengan suara rendah yang berisi informasi sedikit tentang isi rekaman pidato.
- Informasi statistik dikumpulkan untuk menghitung RSV yang Secara khusus, data kuantitatif dihitung yang berkorelasi dengan relevansi dokumen terhadap kueri.
- Teknik Pencarian yang interaktif: sistem mendukung interaksi dengan pengguna untuk meningkatkan kemungkinan keberhasilan
- Setelah presentasi dari daftar peringkat dokumen, pengguna dapat member ikan informasi umpan kembali kepada sistem. Umpan balik informasi dapat terdiri dari referensi ke dokumen yang relevan, atau batas-batas bagian yang relevan, atau dari pencarian
- Sistem pencarian menggabungkan umpan kembali informasi dengan informasi statistik yang diperoleh dari analisis dokumen. Hasil dari kombinasi tersebut mungkin menjadi kueri baru untuk menghasilkan urutan dokumen yang lebih baik atau mungkin menyertakan pencarian tambahan yang diusulkan kepada pengguna akan dimasukkan ke kueri.
B. Sejarah Singkat Temu-kembali Multimedia
Exact-Match Retrieval dokumen multimedia diusulkan oleh Dennis Tsichritzis (1983) dan Stavros Christodoulakis (1986). Best-Match Retrieval citra dilakukan oleh Fausto Rabitti (1987). Lihat juga referensi dalam laporan MULTOS (Thanos,1990).
Pada 1990-1991, Ulla Glavitsch dan Peter Schäuble mulai meneliti Temu- kembali percakapan (Glavitsch dan Schäuble 1992). Baru-baru ini, proyek Video Mail Retrieval (VMR) dimulai di Cambridge University, Inggris (Brown, Foote, Jones, Sparck-Jones, dan Young 1994), (Jones, Foote, Jones, dan Young 1996) dan proyek Temu-kembali informasi multimedia dimulai dalam proyek INFORM EDIA di Carnigie Mellon University (Hauptmann, Witbrock, dan Christel 1995).
Seir ing dengan proyek Temu-kembali percak ap an, kelompok pengen alan percakapan di XEROX PARC dan di MIT Lincoln Lab mulai bekerja pada klasifikasi pesan suara, disebut Topic IDentification (TID) (Wilcox dan Bush 1991), (Rose, Chang, dan Lippmann 1991). referensi yang lebih baru pada TID adalah (Jeanrenaud, Siu, Rohlicek, Mezeer, dan Gish 1994) dan (M cDonough, Ng, Jeanrenaud, Gish, dan Rohlicek 1994).
Konferensi multimedia’91 yang diselenggarakan di Singapura mungkin merupakan konferensi pertama yang memiliki sesi Temu-kembali multimedia. Sejak itu, konferensi multimedia seperti konferensi Multimedia di ACM (Association for Computing Machinery) telah memiliki sedikitnya satu sesi tentang Multimed ia Retrieval yang sering disebut, “Content-Based Retrieval“.
C. Jenis-Jenis Sistem Temu Kembali Multimedia
Berikut adalah jenis-jenis sistem temu kembali multimedia:
- Temu Kembali Audio berbasis Konten (Conten Based Audio Retrieval)
- Temu Kembali video berbasis Konten (Content Based Video Retrieval)
- Temu Kembali Citra Berbasis Konten (Content Based Image Retrieval)
- Temu Kembali Teks Berbasis Konten (Content Based Text Retrieval)
- Pengukuran Jarak Antar Dua Histogram
- Fitur warna merupakan fitur yang paling banyak digunakan pada sistem CBIR.
- Banyak diantaranya mengunakan image color histogram.
- Color histogram antara dua gambar tadi kemudian dihitung jaraknya.
- Gambar yang memiliki jarak paling kecil, merupakan solusinya.
- Dimisalkan ada dua gambar dengan histogram 4 warna yang sudah terkuantisasi sebagai berikut:

- Rumus menghitung jarak:
![]()
- Sehingga:
![]()
- Cara lain dg rumus Euclidan
![]()
- Sehingga
![]() 2. Arsitektur CBIR
2. Arsitektur CBIR
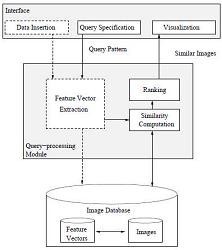
- Bagian Arsitektur CBIR
- Interface :bagian untuk interaksi antara pengguna dengan sistem CBIR melalui aplikasi GUI (Graphical User Interface). Terdiri dari:
- Data Insertion : untuk memasukan citra yang akan di ekstrasi.
- Query Specification untuk menentukan citra yang akan dijadikan citra query serta menentukan metode ekstraksi fitur.
- Visualization untuk menampilkan citra query dan citra hasil
- Interface :bagian untuk interaksi antara pengguna dengan sistem CBIR melalui aplikasi GUI (Graphical User Interface). Terdiri dari:
- Query-processing module, terdiri dari:
- Feature vector extraction untuk mengekstraksi baik citra yang ada didatabase citra maupun citra
- Similarity Computation digunakan untuk menghitung kesamaan fitur citra.
- Ranking digunakan untuk mengurutkan citra yang memiliki tingkat kemiripan dengan citra
- Image Database, terdiri dari
- Feature Vectors yang digunakan untuk menyimpan hasil ekstraksi fitur Dan disimpan didalam database derby.
- Images merupakan database citra yang secara fisik berupa folder yang didalamnya terdapat kumpulan citra
Referensi
- http://sutikno.blog.undip.ac.id/files/2013/06/Materi-1-Relevance-Feedback1.pdf2222
- http://library.binus.ac.id/eColls/eThesisdoc/Bab2/2011-1-00327-if%202.pdf
Download