Temu Balik Informasi (Information Retrieval)
A. Pengertian Temu Balik Informasi (Information Retrieval)
- Temu kembali informasi sebagai suatu proses pencarian dokumen dengan menggunakan istilah luas untuk mengidentifikasi dokumen yang berhubungan dengan subjek tertentu. Hal ini berarti bahwa sistem temu balik informasi merupakan jalan menuju perolehan informasi yang sesuai dengan kebutuhan pengguna. ( Hardi (2006: 22))
- Naïve: Find all documents containing the following words Advanced: „Leading the user to those documents that will best enable him/her to satisfy his/her need for information“[Robertson 1981] (Modul Information Retrieval Humboldt Universitat, Zuberlin)
- Temu kembali informasi atau information retrieval merupakan proses dimana pengguna dapat menemukan informasi yang dibutuhkan pada penyedia informasi dengan dibantu oleh sistem yang sudah disediakan. (Devita Kusumawardani, 2013)
- Sistem Temu Balik Informasi (Information Retrieval) adalah ilmu mencari informasi dalam suatu dokumen, mencari dokumen itu sendiri dan mencari metadata yang menggambarkan suatu dokumen. Sistem Temu Balik Informasi merupakan cabang dari ilmu komputer terapan (applied computer science) yang berkonsentrasi pada representasi, penyimpanan, pengorganisasian, akses dan distribusi informasi. (Menurut Wibowo 2012 dalam Devita Kusumawardani 2013)
- Information retrieval adalah sebuah proses untuk menemukan kembali informasi yang dibutuhkan dari sebuah sistem penyimpanan dan penelusuran informasi. (Putung, dkk 2016)
B. Gambaran Umum Temu Balik Informasi
- Gambaran Information Retrieval

Gambar Dokumen
(Sumber: Modul Konsep Dasar Sistem Temu Kembali Informasi Univ. Brawijaya)

Gambar Penyimpanan Terorganisasi
(Sumber: Modul Konsep Dasar Sistem Temu Kembali Informasi Univ. Brawijaya)
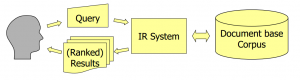
Gambar Sistem IR
(Sumber: Modul Information Retrieval Humboldt Universitat, Zuberlin)
C. Pokok Bahasan Temu Balik Informasi
- Komponen Temu Balik Informasi
Sistem temu balik informasi memiliki beberapa komponen. Menurut Hasugian (2007:3) ada lima, yaitu:
- Pengguna STBI adalah orang yang menggunakan atau memanfaatkan STBI dalam rangka kegiatan pengelolaan dan pencarian informasi. Berdasarkan perannya, pengguna STBI dibedakakan atas 2 (dua) kelompok yaitu pengguna (user) dan pengguna akhir (end user). Pengguna (user) adalah seluruh pengguna STBI yang menggunakan STBI baik untuk pengelolaan (input data, backup data, maintenance, dsb) maupun untuk keperluan pencarian atau penelusuran informasi, sedangkan pengguna akhir (end user) adalah pengguna yang hanya menggunakan STBI untuk keperluan pencarian dan atau penelusuran informasi.
- Query adalah format bahasa permintaan yang diinput (dimasukan) oleh pengguna kedalam STBI. Dalam interface (antarmuka) STBI selalu disediakan kolom/ruas sebagai tempat bagi pengguna untuk mengetikkan (menuliskan) query nya. Dalam OPAC perpustakaan disebut “Search expression”. Pada kolom itulah pengguna mengetik/ menuliskan bahasa permintaanya (query), dan setelah query itu dimasukkan selanjutnya mesin akan melakukan proses pemanggilan (recall) terhadap dokumen yang diinginkan dari database.
- Dokumen adalah istilah yang digunakan utnuk seluruh bahan pustaka, apakah itu artikel, buku, laporan penelitian dsb. Seluruh bahan pustaka Universitas Sumatera Utara dapat disebut sebagai dokumen. Dokumen dalam bahasa STBI online adalah seluruh dokumen elektronik (digital) yang telah diinput (dimasukkan) dan disimpan dalam database (pangkalan data).
- Index Dokumen yaitu istilah atau kata yang disimpan kedalam database yang berfungsi sebagai representasi sebuah dokumen.
- Pencocokkan (Matcher Fungtion) Pencocokkan istilah (query) yang dimasukkan oleh pengguna dengan indeks dokumen yang tersimpan dalam database dan dilakukan oleh mesin komputer
(Sumber: Materi Temu Kembali Informasi Universitas Sumatera Utara)
D. Empat Model Klasik Information Retrieval
- Logical models – sejak lama menggunakan Boolean logic (and, or, not). Alternatif temuan hanya dua: cocok dan tidak cocok.
- Vector processing models – memperlakukan indeks sebagai multidimensional information space. Dokumen dan query diwakili oleh nilai-nilai vektor sehingga keduanya memperlihatkan posisi dekat atau jauh. Non binary, degree of similarity.
- Probabilistic models – berasumsi bahwa sistem IR bertugas membuat urut-urutan (ranking) dokumen sesuai kemungkinannya dalam menjawab kebutuhan informasi. Menggunakan teori probabilitas untuk menghitung nilai relevansi dokumen.
- Cognitive models – memfokuskan diri pada interaksi antara pengguna dan sistem IR, tidak hanya dalam persoalan dokumen dan query. Lebih mempersoalkan antar-muka daripada proses komputasi penemuan dokumen.
(Sumber: Ragam Teori Informasi, Putu Laxman Pendit, Ph.D, Perpustakaan Pusat Universitas Indonesia)
E. Penerapan Temu Balik Informasi
Penerapan temu balik informasi dalam dunia nyata yaitu:
- Search engine (Mesin Pencari) seperti Google, Yahoo, Wolfram Alpha, Meta Ger, dan lain-lain.
(Sumber: Modul Information Retrieval Humboldt Universitat, Zuberlin)
- Digital Library
(Sumber: Modul Konsep Dasar Sistem Temu Kembali Informasi Univ. Brawijaya)
F. Bahasa Pemrograman yang digunakan
Bahasa pemograman yang dipakai pada temu balik informasi yaitu Turbo Assembler dari borland, Macro Assembler dari microsoft, pascal, visual basic, Sql (Structured Query Language), php.
(sumber: Skripsi Delavenia Luis dari STMIK TIME Medan tahun 2015, Perancangan information retrieval system dengan metode extended boolean and savoy).
link File Presentasi : Temu Balik Informasi 1
link referensi :
http://imamcs.lecture.ub.ac.id/files/2013/09/02-Konsep-Dasar_IR_ABD_IL1314IC.pdf
http://eprints.rclis.org/10294/1/Ragam_Teori_Informasi.pdf
http://ejournal.stmik-time.ac.id/index.php/skripsiTIMES/article/download/139/60